

Classifier
Search > Models > Classifier
The Category Classifier is a model that has been specifically developed to assist in the automatic categorization of user-generated queries or textual inputs. This model is designed to analyze and classify text data into predefined categories or labels based on its content, allowing for efficient and accurate organization of information.
Key Features:
- User-Friendly Input: The classifier is user-friendly, accepting textual queries or inputs from users in natural language. This makes it accessible and easy to use for individuals with varying levels of technical expertise.
- Predictive Power: The model harnesses advanced Natural Language Processing (NLP) techniques and harnesses the capabilities of the Albert model to discern the most pertinent category for a given query. It taps into intricate language patterns, semantics, and contextual cues within the text, enabling it to deliver highly precise predictions.
- Versatile Categorization: The classifier is versatile, accommodating a wide range of categories or labels. It can be customized to work with various industries or domains, making it adaptable for different applications.
- Real-Time Predictions: It provides real-time predictions, allowing for quick and automated classification of user queries as they are submitted. This enables immediate responses or actions based on the categorized information.
- Continuous Learning: The model can be trained and retrained with new data, enabling it to adapt and improve over time. This ensures that it remains effective in handling evolving user queries and content.
- Scalable: The classification model is scalable and can handle a high volume of queries efficiently. Whether there are a few or thousands of queries to classify, the model can process them in a timely manner.
Enhanced Shopping Experience:
Within e-commerce platforms, this model plays a pivotal role in optimizing the shopping experience by intelligently categorizing product search queries. Its proficiency in swiftly and accurately categorizing user queries significantly enhances the efficiency of the search process and ultimately aids users in swiftly discovering the items they desire. Whether users are seeking specific products or exploring a broad range of options, the model ensures that they receive targeted and relevant search results, streamlining their journey toward finding the perfect products. This capability not only benefits customers but also contributes to higher user satisfaction, increased conversion rates, and improved overall platform usability.
Classifier Model Console:
Now, we will proceed through the stages, starting from data preparation and training, all the way to the deployment of the final model.
There are 5 following stages:-
- DATAPREP
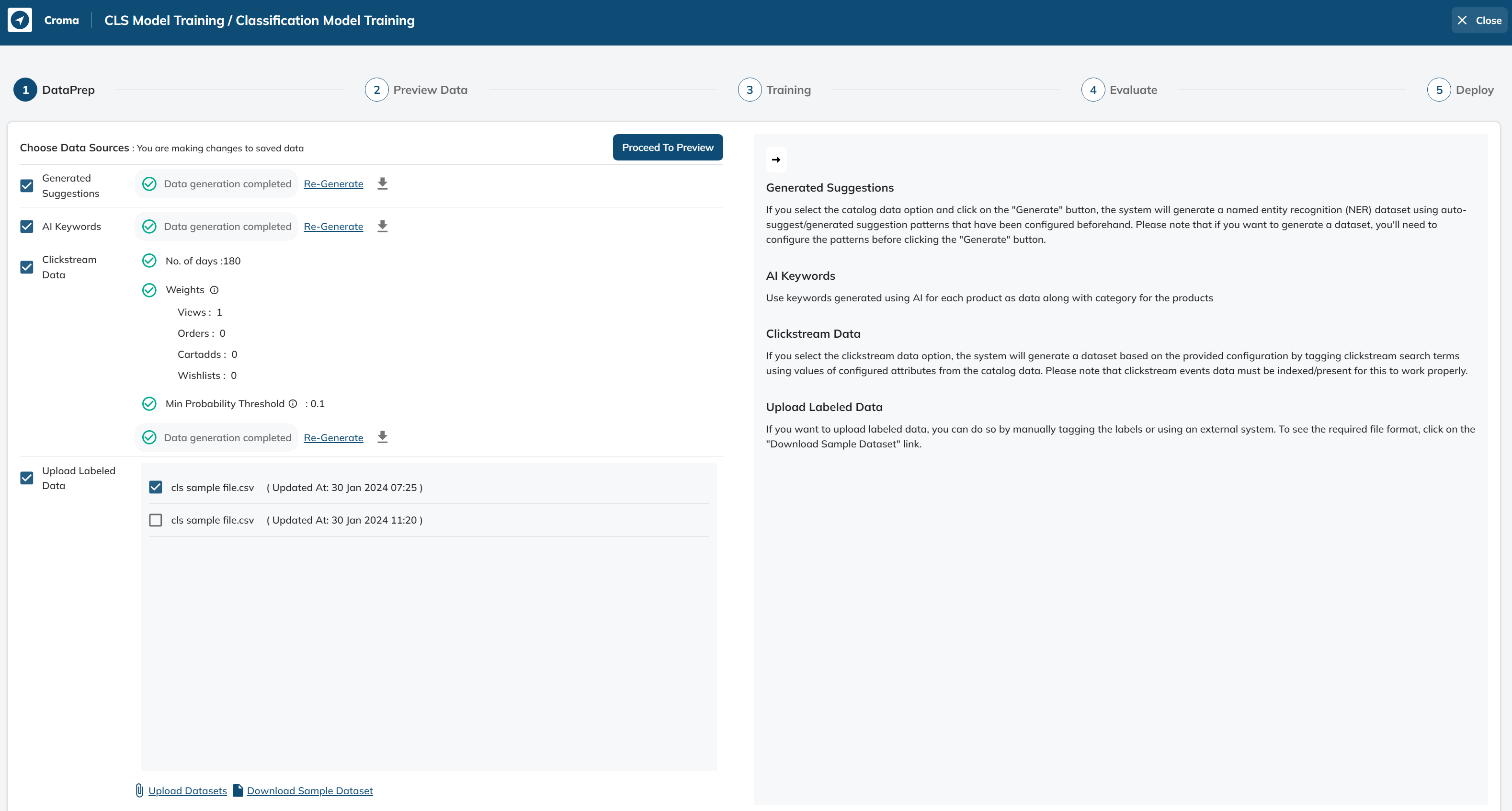
In this stage, we prepare the data which will be used for training our classification model.
We have three options to choose from as the data source for data preparation:-
- Generated Suggestions -
Accessing the Generated Suggestions function involves the processing of generated suggestions data to prepare the final dataset containing queries and their associated categories.
Pre-Requisites -
- Before proceeding, ensure that the generated suggestions data is readily available. If it's not present, you will need to configure the patterns for generating suggestions and execute the process to generate the required Generated Suggestions data. This step is crucial as it serves as the foundation for catalog data preparation.
Data Generation -
-
Obtain generated suggestion datasets
-
Remove rows with missing or NaN values in the 'category' column.
-
Extract and retain only the 'search_term' and 'category' columns.
-
Standardize data types: convert string representations of lists to lists and integer lists to sets of string representations.
-
Clean and preprocess the data: rename columns, convert 'query' values to lowercase, drop NaN values, filter out empty 'category' sets, convert 'category' sets to lists, and remove empty strings from 'category' lists.
-
Filter the dataset to include rows with a non-empty 'category' column.
-
Generate preview data using the filtered df
- AI Keywords -
The "AI Keywords" processing stage involves the utilization of both "AI Product Keywords" and "AI Category Keywords" for the purpose of data preparation. This data preparation process ultimately yields the final dataset consisting of queries and their respective categories.
Pre-Requisites -
- Before proceeding, ensure that both "AI Product Keywords" and "AI Category Keywords" tables are readily available. If they are not present, you will need to generate both tables from Configurations → Autosuggest → Sources → AI Suggestions. This step is crucial as it serves as the foundation for AI keywords data preparation.
Data Generation -
-
Fetch the category hierarchy.
-
Filter out datasets containing AI Product Keywords when joining with the catalog dataset using the category hierarchy.
-
Retrieve the data for the AI category with the lowest keywords and explode the keywords.
-
Concat both datasets.
-
Combine queries by grouping them and aggregate categories into a list.
- Clickstream Data -
The "Clickstream Data" processing stage involves the utilization of both "Catalog Data" and "Search Product Metrics Data" for the purpose of data preparation. This data preparation process ultimately yields the final dataset consisting of queries and their respective categories.
Pre-Requisites -
-
Catalog Data
-
Search Product Metrics data
Sub-param -
The "No. of Days" sub-parameter plays a pivotal role in determining the time window for which the "Search Product Metrics Data" should be considered during the data preparation process. This time window reflects the period over which user interactions and behaviors are taken into account, allowing for the creation of a relevant and up-to-date dataset of queries and categories.
In essence, by specifying the "No of Days," you define the recency and relevance of the data used for preparing the final dataset, ensuring that it accurately reflects user behavior and preferences within the chosen timeframe.
Data Generation -
- Get the query data
A. Retrieves data from a table named "search_product_metrics."
B. Aggregate the metrics (total clicks, total products in cart, total products checked out) for each unique combination of search term and product id.
C. Further filter out the aggregated results based on specified conditions for total clicks, products in the cart, and checked-out products.
Conditions:
a. Total clicks are greater than or equal to 8, total products in the cart are greater than or equal to 1, or total checked-out products are greater than or equal to 1.
c. Alternatively, total clicks are greater than or equal to 5, total products in the cart are greater than or equal to 2, or total checked-out products are greater than or equal to 2.
-
Retrieve catalog data containing categories at levels l0, l1, and l2, get the final category, and merge the query data and catalog data on product id.
-
Initialize a 'freq' column in the DataFrame with a value of 1 for each row.
-
Aggregate the DataFrame based on 'search_term' and 'final_category,' summing the 'freq' values.
-
Calculate the total frequency for each 'search_term' and store it in a dictionary
-
Compute probabilities based on the 'freq' and 'search_term' columns.
-
Filter and process the DataFrame, then save the result to a CSV file and generate the preview data, considering a minimum click threshold
- Upload Labelled Data -
This functionality enables users to upload their own datasets for model training, provided that the data adheres to a specific schema.
Pre-Requisites -
- The schema consists of two columns: one for queries (containing text strings) and another for categories (containing a list of categories in string format). This structured format ensures that the data can be effectively processed and used for training the classification model.
- PREVIEW DATA
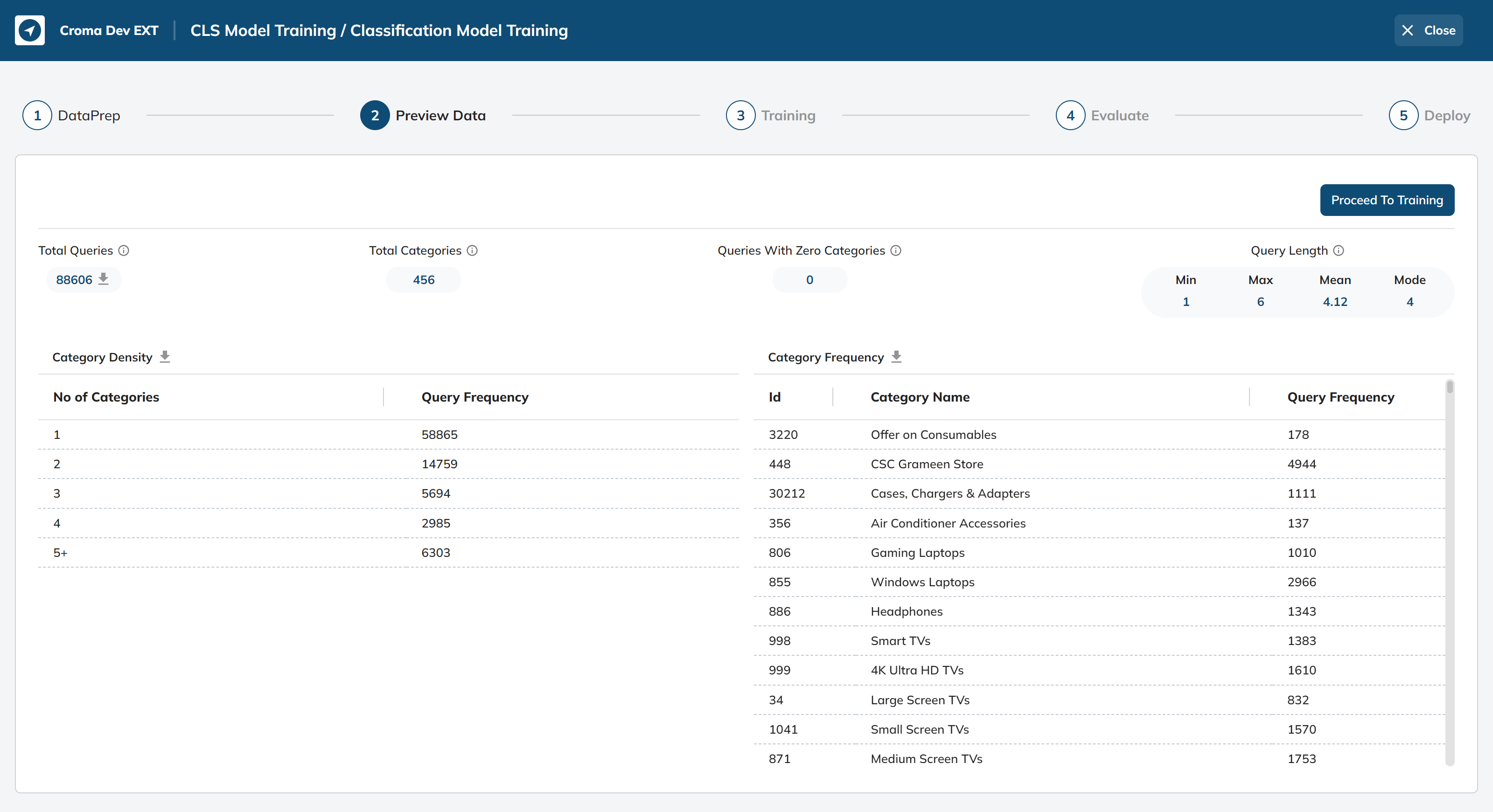
In this stage, we provide an overview of the data that will be used for training our classification model.
Total Queries:
This represents the total number of user queries made on the platform.
Total Categories:
This indicates the total number of product categories available after the data preparation.
Queries With Zero Categories:
This means that every query made by users corresponds to at least one product category.
Query Length:
These statistics provide information about the length of user queries in terms of the number of characters.
Category Density:
This section provides the distribution of queries among different categories.
- No of Categories: The number of categories a query falls into.
- Query Frequency: The number of queries falling into each category counts.
Category Frequency:
This section provides information about the most frequently queried categories and their respective query frequencies.
- Id: The unique identifier for each category.
- Category Name: The name or description of the category.
- Query Frequency: The number of times queries were made for each category.
- TRAINING
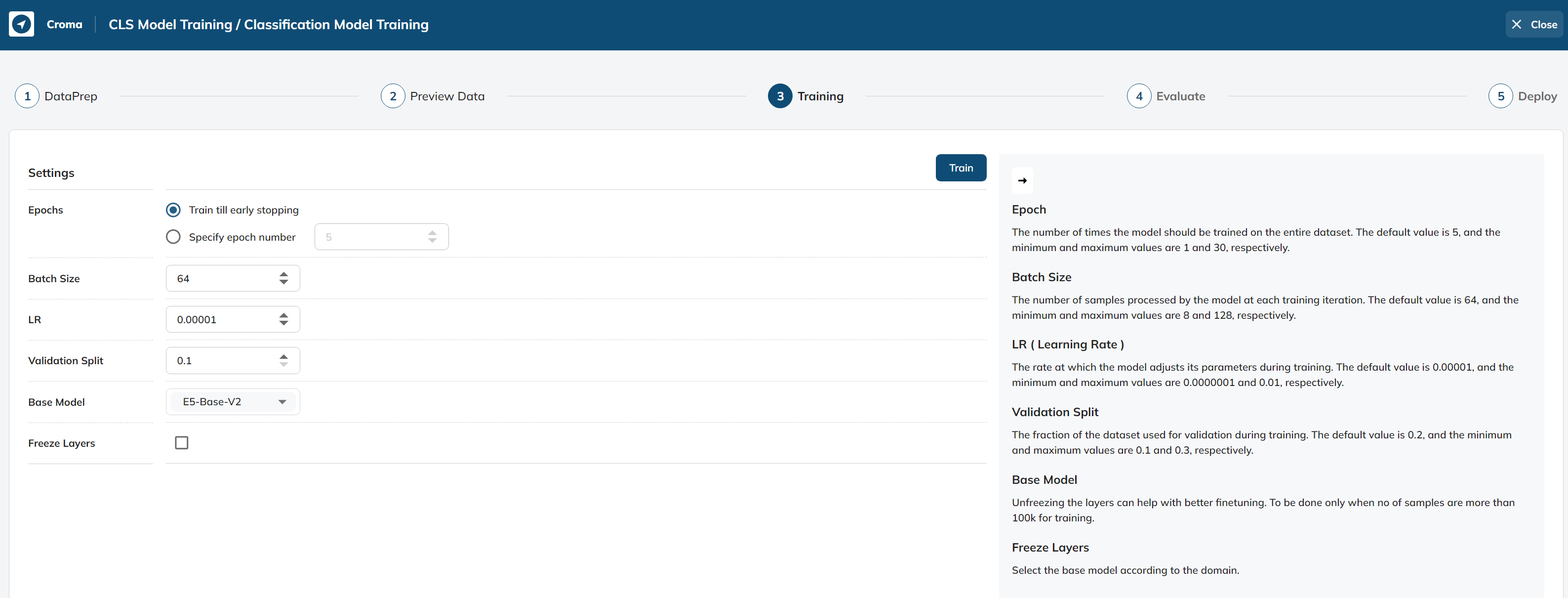
Epochs:
Definition: The number of times the model should be trained on the entire dataset.
Train till early Stopping: Training will utilize 1000 epochs and will halt upon early stopping.
Specify epoch number: Users are able to input the desired epoch count.
- Default Value: 5
- Minimum Value: 1
- Maximum Value: 30
Purpose: Epochs determine how many times the model will iterate over the entire dataset during training. A higher number of epochs can lead to better model performance, but it may also increase the risk of overfitting, especially if the dataset is small.
Batch Size:
Definition: The number of samples processed by the model at each training iteration.
- Default Value: 64
- Minimum Value: 8
- Maximum Value: 128
Purpose: Batch size affects the speed and memory requirements of training. A smaller batch size may result in slower training but can be useful for fine-tuning. A larger batch size speeds up training but may require more memory.
LR (Learning Rate):
Definition: The rate at which the model adjusts its parameters during training.
- Default Value: 0.00001
- Minimum Value: 0.0000001
- Maximum Value: 0.01
Purpose: The learning rate controls the step size in parameter updates during optimization. A small learning rate can lead to slower convergence but is more stable, while a large learning rate can speed up training but may result in overshooting the optimal parameter values.
Validation Split:
Definition: The fraction of the dataset used for validation during training.
- Default Value: 0.1
- Minimum Value: 0.1
- Maximum Value: 0.3
Purpose: The validation split determines the portion of the dataset that is set aside for validation to monitor the model's performance during training. A larger validation split can provide better feedback on model performance but reduces the size of the training dataset.
Base Model:
The base model can be selected from this option based on the domain.
Freeze Layers:
Freezing the base layers of the model can enhance its performance.
The training process of the classification model can be a time-consuming task, and the duration of training largely depends on the size of the dataset and the complexity of the model.
Post-Training -
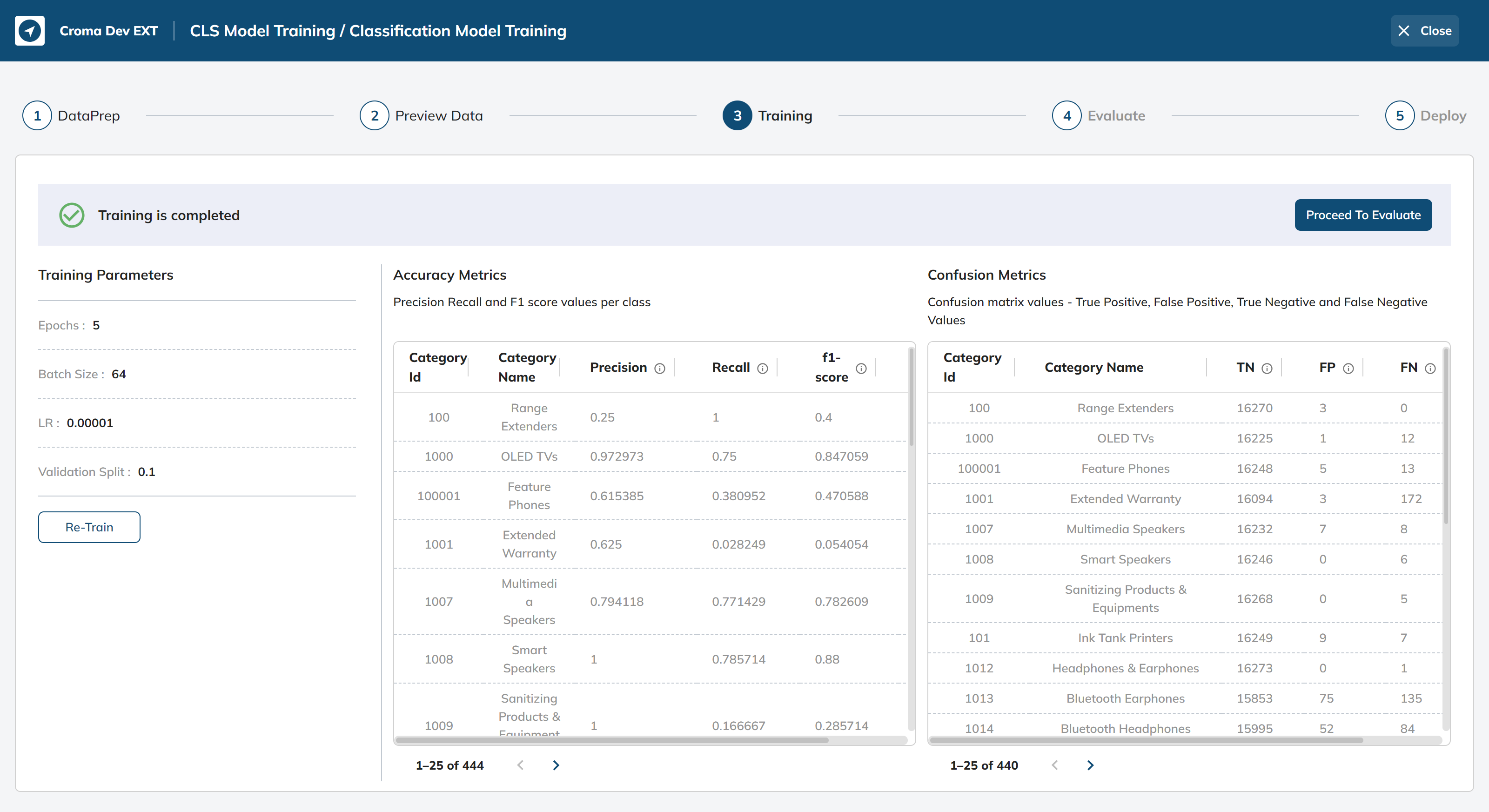
Upon the successful completion of training, our model's performance evaluation will be facilitated through the presentation of the following tables. These tables serve as essential tools to assess and measure the effectiveness and accuracy of the trained model, allowing us to gain valuable insights into its capabilities and areas of improvement. Through these tables, we can comprehensively evaluate how well the model performs in categorizing queries, making informed decisions, and enhancing the overall user experience.
Accuracy Metrics:
The table provides precision, recall, and F1-score values for different categories/classes.
- Precision: Precision is the ratio of true positives to the total number of predicted positives. It measures the accuracy of positive predictions.
- Recall: Recall is the ratio of true positives to the total number of actual positives. It measures the model's ability to identify all relevant instances.
- F1-score: The F1-score is the harmonic mean of precision and recall. It provides a single metric to balance precision and recall.
- Support: The support indicates the number of instances of each class in the dataset.
Confusion Metrics:
The confusion matrix provides details about how well the model performed for each class. It includes four values:
- True Negative (TN): The number of true negatives, instances correctly predicted as negative.
- False Positive (FP): The number of false positives, instances incorrectly predicted as positive.
- False Negative (FN): The number of false negatives, instances incorrectly predicted as negative.
- True Positive (TP): The number of true positives, instances correctly predicted as positive.
The confusion matrix values allow you to calculate precision, recall, and F1-scores for each class based on the classification results.
- EVALUATE
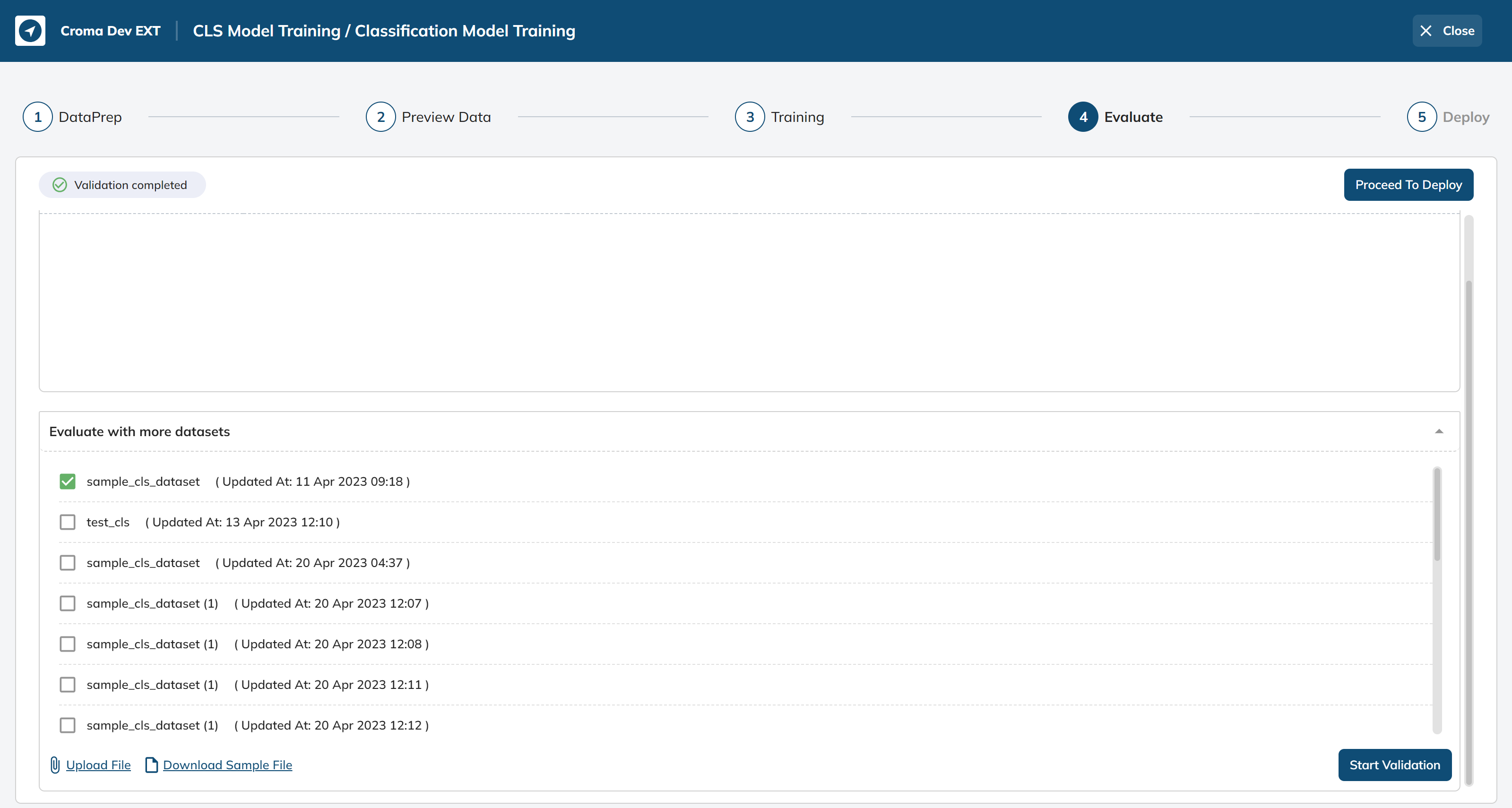
In this particular stage, we facilitate the evaluation of our classification model by providing the following sample datasets:-
These sample datasets are meticulously prepared and formatted to mimic the structure of real-world data. By offering these datasets, we aim to assess the model's performance in accurately categorizing user queries.
The primary purpose of these sample datasets is to gauge the model's effectiveness in assigning appropriate categories to a set of predefined queries. This evaluation process allows us to calculate scores that reflect the model's precision, recall, and F1-score, which are key metrics for measuring its classification performance.
The sample dataset can be uploaded for the evaluation of the model trained to check the performance of the model. After selection, we can click the “Start Validation” button.
Following the evaluation process, the system generates essential scores, including precision, recall, F1-score, and accuracy.
Additionally, it provides the option to view or download the confusion matrix, accuracy matrix, and prediction report files. These files offer detailed insights into the model's performance, such as actual categories, predicted categories, and the discrepancies between them.
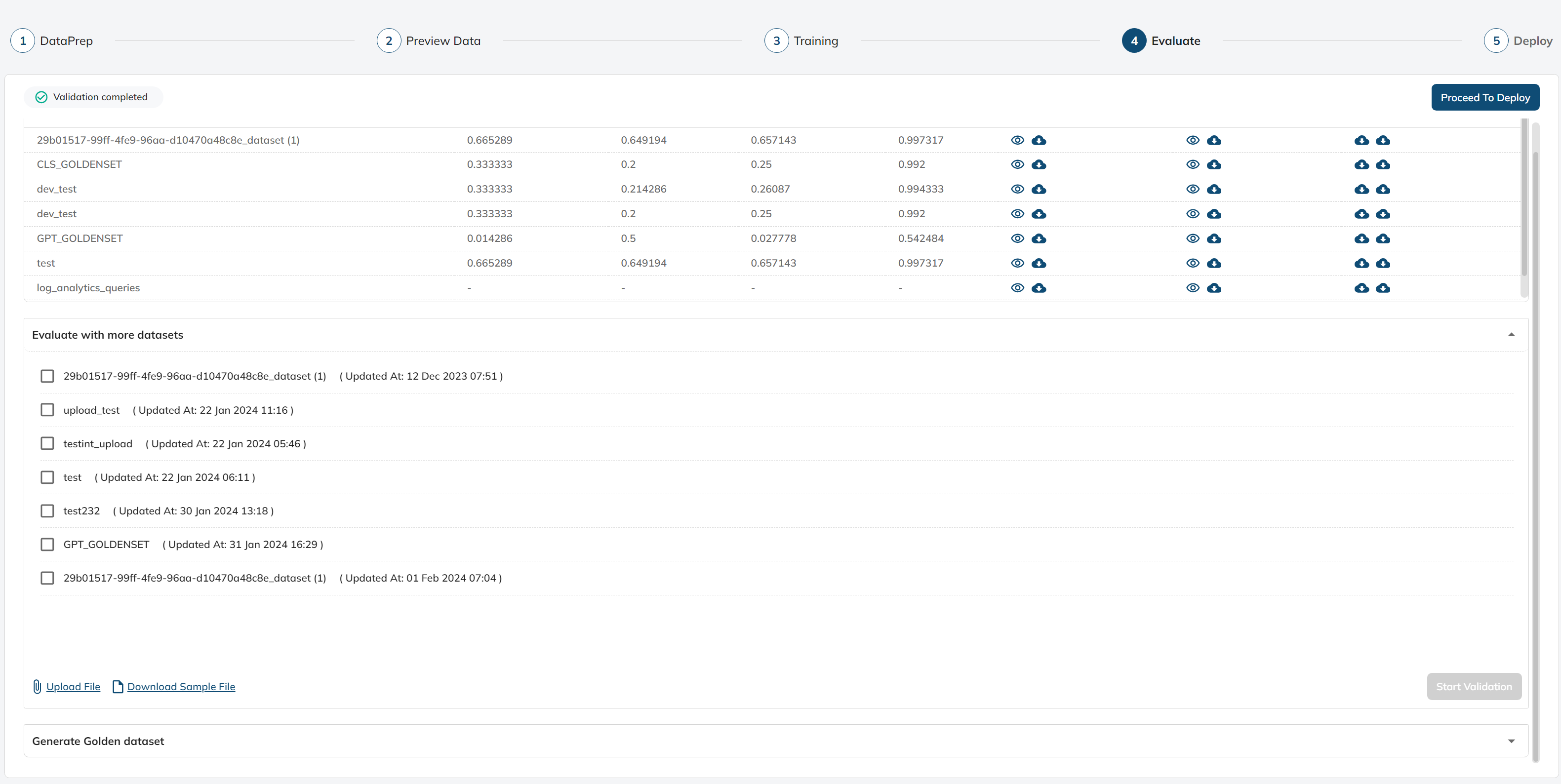
Generate Golden Dataset:
Generate golden dataset section will help in creating golden dataset from scratch which will be used for evaluation. We can select between sample and full. Sample is for generating goldenset for 500 records and can be downloaded for verification also. Full generation will be generated for 20,000 records and once the generation is completed, it will be sent to the dataset group which can be used for evaluation.
Generation:-
- Retrieve the first queries from the past 180 days.
- Split the results into two sets: the top 10,000 and a random selection of 10,000 from the remaining 90,000.
- Generate vectors for both the queries and all category names.
- Compare the vectors of the queries with those of the categories and select the top 10 categories.
- Submit these queries and categories to GPT for verification of relevance.
- Filter out irrelevant categories to obtain the desired golden dataset containing queries and relevant categories.
- DEPLOY
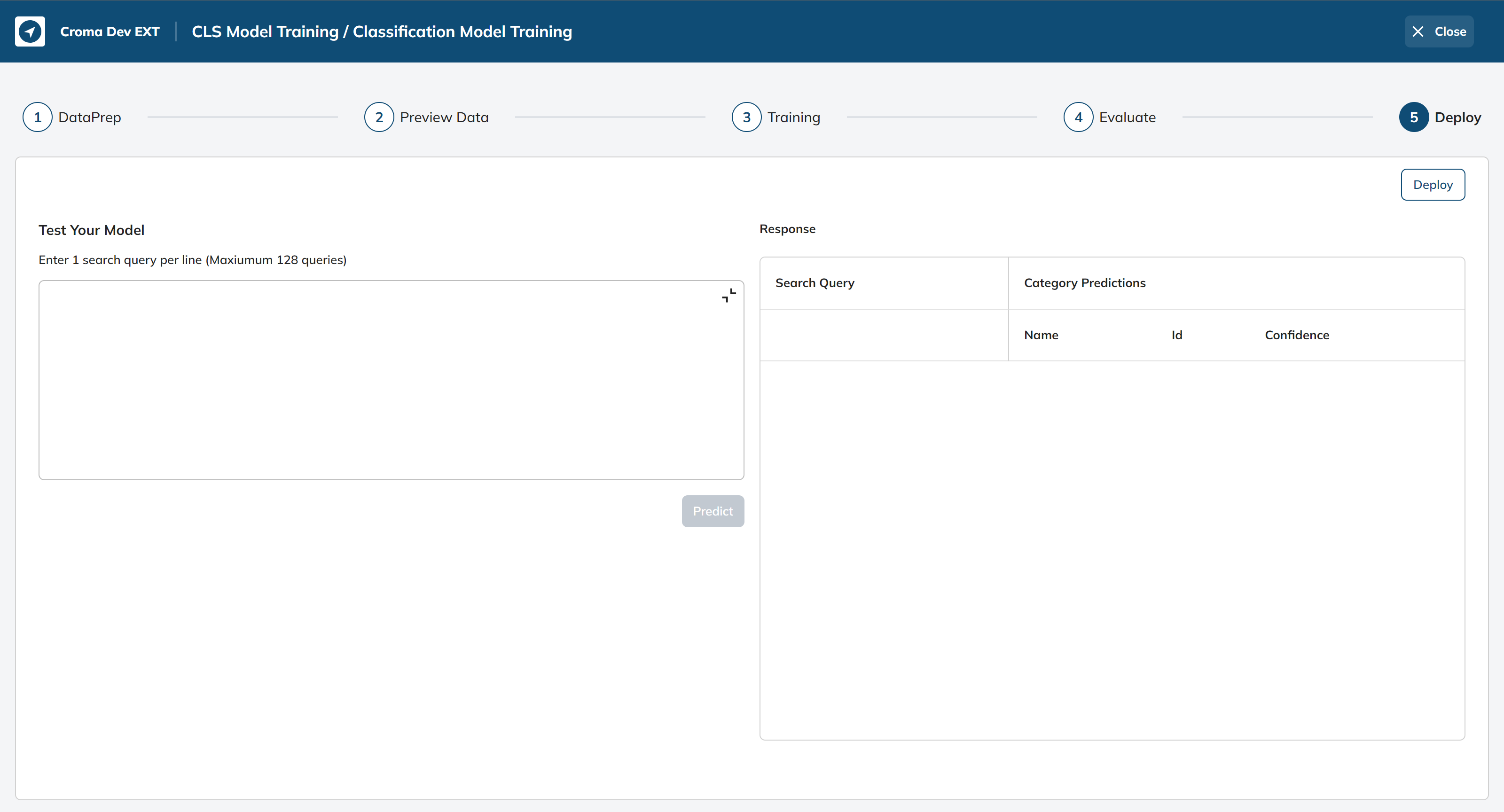
After successfully training and evaluating the model, the next crucial step is deployment, where the model is made accessible and operational for use in real-world applications or services. This phase marks the transition from a research or development environment to practical, everyday use.
Next, in the Test Your Model we will provide a query - “Apple iPhone 13“.
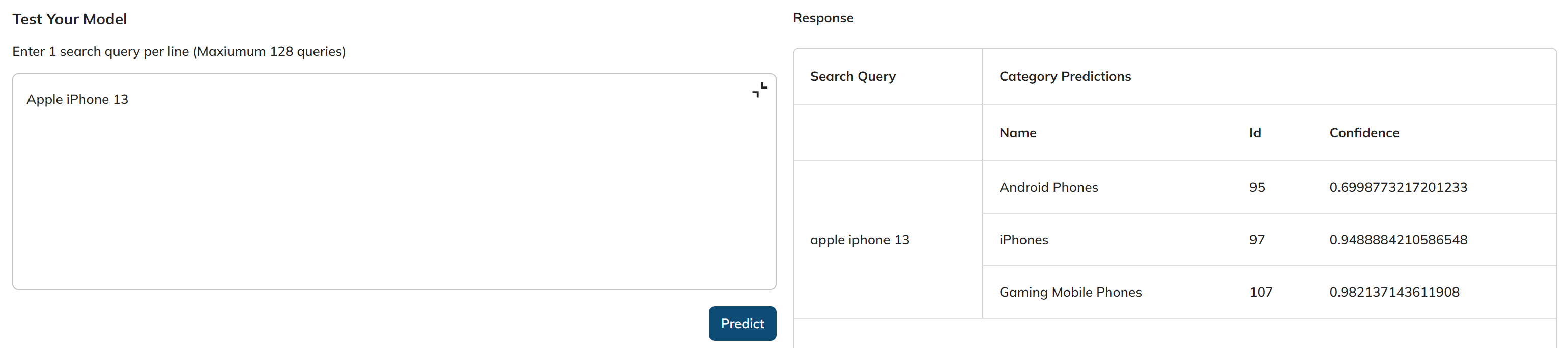
- Test Your Model: This is a stage in the deployment process where you can test the deployed model's performance by providing search queries and receiving category predictions. To get the response, we can click the “Predict” button.
- Response: This will represent the response or results of the model's predictions for the provided search queries.
- **Search Query**: The input search queries provided by the user. - **Category Predictions**: The predicted categories or labels generated by the deployed model for each search query. - **Name**: The name or label associated with the predicted category. - **Id**: An identifier associated with the predicted category. - **Confidence**: The model's confidence or certainty level in its predictions is typically represented as a decimal value ranging from 0 to 1, with 1 indicating the highest level of confidence.Once we have verified that the model is functioning flawlessly, we can proceed to deploy it for practical use by simply clicking the "Deploy" button.
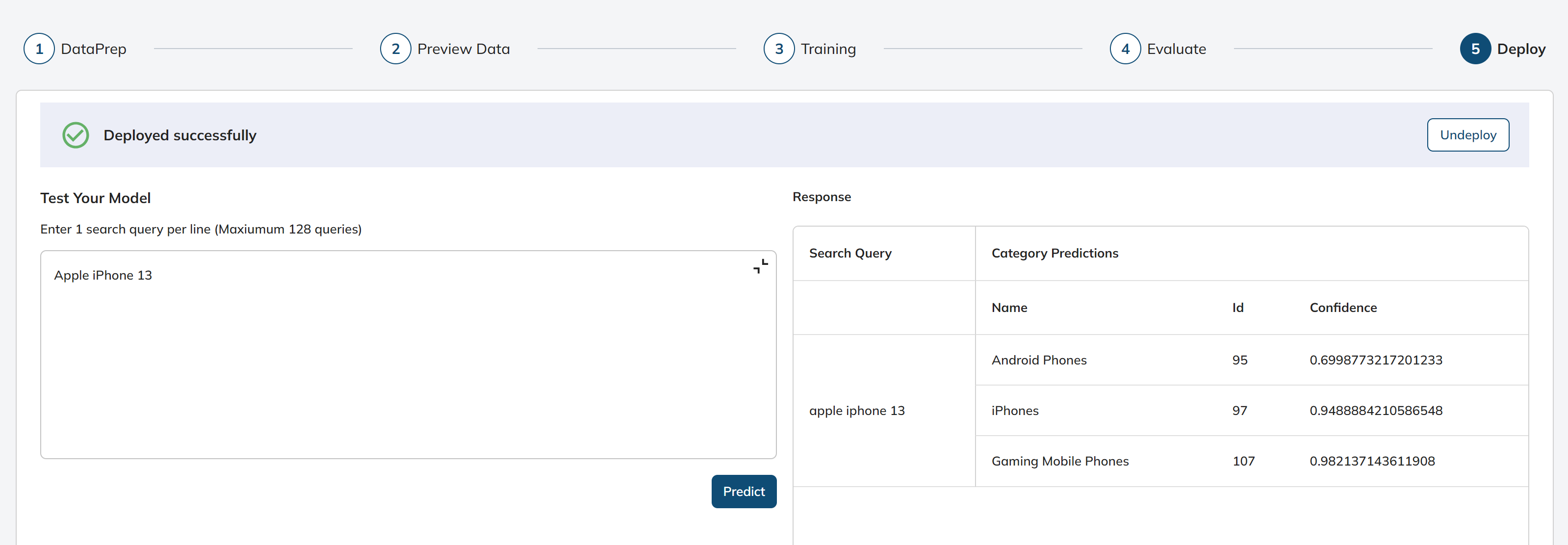
If needed, we can also deactivate or remove the deployed model by clicking the "Undeploy" button.