

Spell
Search > Models > Spell
Overview:
Spell check model plays a crucial role in ensuring accurate and relevant search results for users. The primary goal is to enhance the search experience by correcting spelling errors in user queries, ultimately leading to improved product discovery and customer satisfaction.
Why it's Essential:
- User Engagement:
Users on an e-commerce platform may have specific product names, brands, or model numbers in mind. Spell check ensures that even minor typos or misspellings don't hinder their ability to find what they're looking for.
- Conversion Rates:
Accurate search results contribute to higher conversion rates. When users can easily locate the products they want, they are more likely to make a purchase.
- User Experience:
A seamless and error-free search experience enhances user satisfaction, encouraging repeat visits and positive reviews.
- Product Discovery:
E-commerce platforms often have a vast inventory. Spell check assists users in discovering relevant products, especially when dealing with a diverse range of brand names, product variants, and technical terms.
- Competitive Edge:
Offering a robust spell check system provides a competitive edge by delivering a superior search experience compared to platforms that lack this feature.
Spell Model Console:
Now, we will proceed through the stages, starting from data preparation and training, all the way to the deployment of the final model.
There are 5 following stages:
1. DATAPREP:
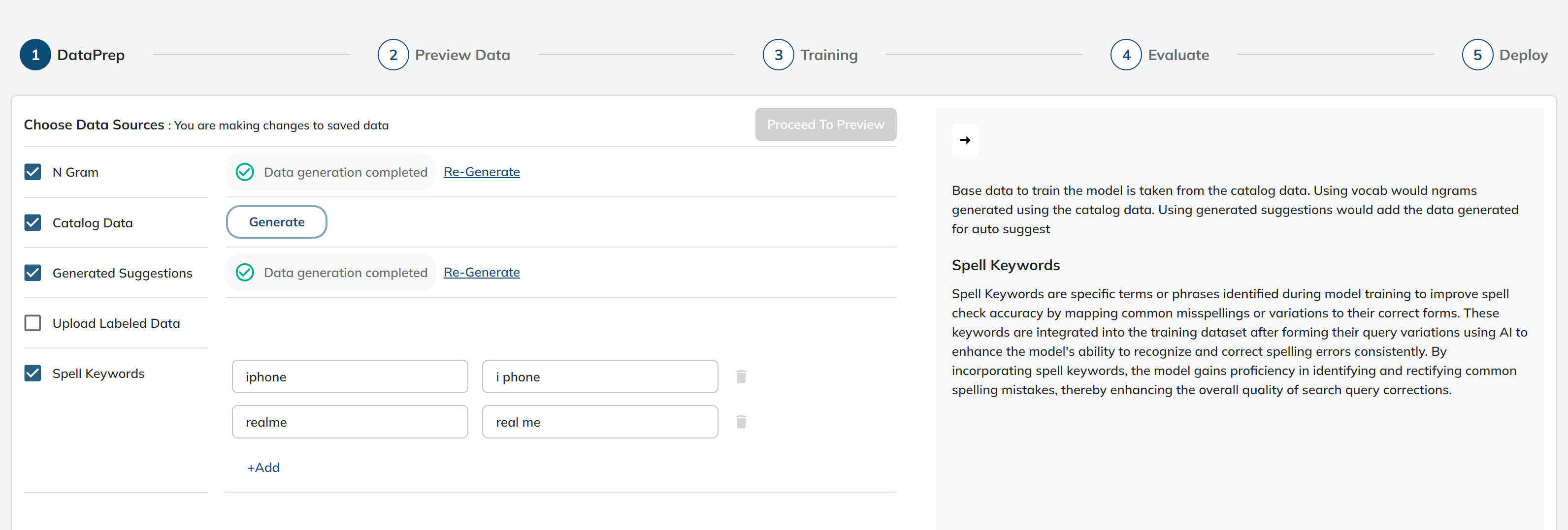
In this stage, we prepare the data which will be used for training our spell check model.
We have four options to choose from as the data source for data preparation:-
Catalog Data- Accessing the Catalog Data function involves the usage of titles from catalog to use them as correct queries
Generated Suggestions
N Grams- We use stored ngrams and unigrams in the dataprep
Upload Labelled Data- This functionality enables users to upload their own datasets for model training, provided that the data adheres to a specific schema.
Pre-Requisites- The schema consists of two columns: one for “correct_queries” and another for “wrong_queries” (both containing the test strings) This structured format ensures that the data can be effectively processed and used for training the spell model.
Spell Keywords- Spell Keywords are specific terms or phrases identified during model training to improve spell check accuracy by mapping common misspellings or variations to their correct forms. These keywords are integrated into the training dataset after forming their query variations using AI to enhance the model's ability to recognize and correct spelling errors consistently. By incorporating spell keywords, the model gains proficiency in identifying and rectifying common spelling mistakes, thereby enhancing the overall quality of search query corrections.
Insights of Dataprep:
- Proper cleaning of catalog titles
- Addition of model names on top of ngrams if selected data source is ngrams
- Wrong queries generation using GPT:
- For the top k unigrams(based on their frequency across all the titles) we are generating 20 incorrect words using GPT incrementally.
- For each query in all the correct queries that we have generated, we generate incorrect query using 2 heuristics(remove_space & random_char_swap) + used gpt generated incorrect words.
- We split the query into words and find words which are present as a correct word in gpt generated
- If the data source is ngrams then we are taking top unigrams and adding 's' to them at the end if they not ending with 's'. Adding them directly in the data as correct and incorrect queries
2. PREVIEW DATA:
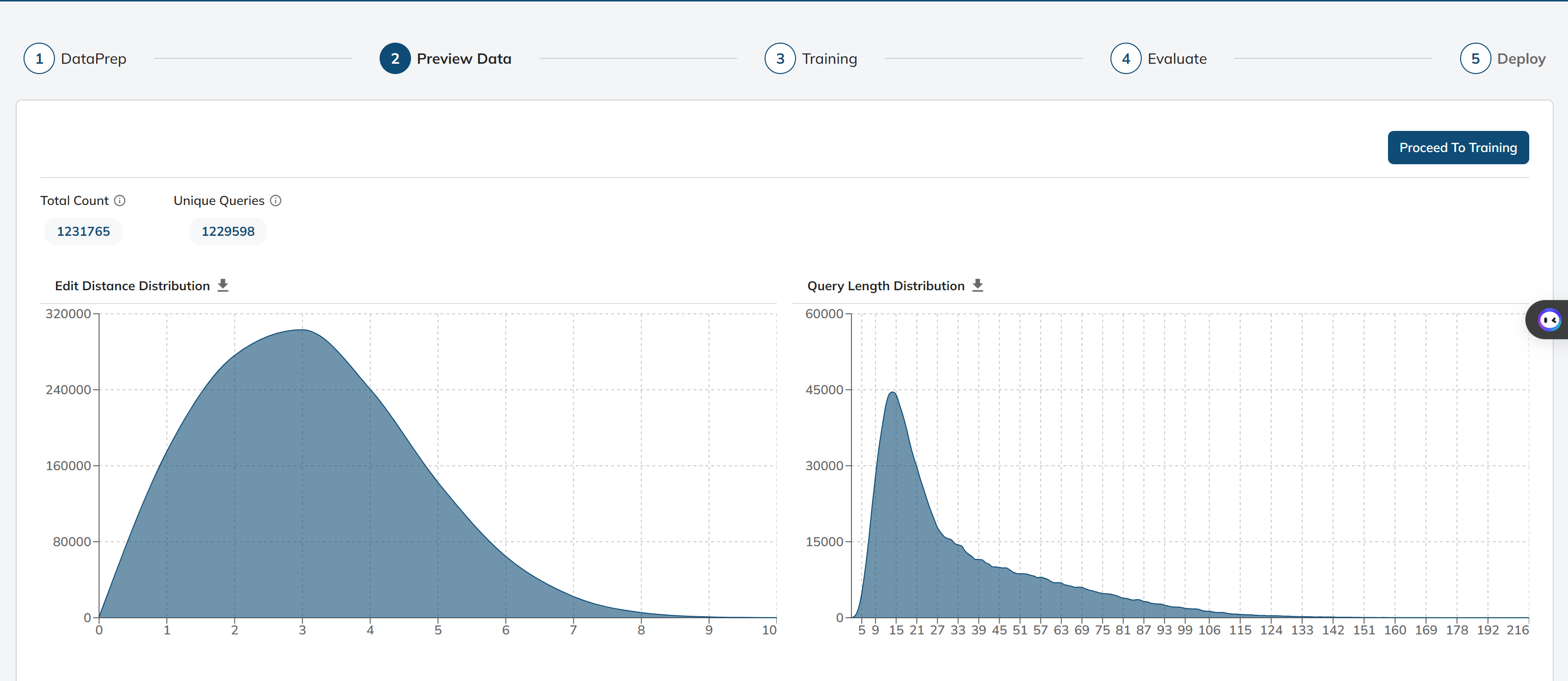
In this stage, we provide an overview of the data that will be used for training our spell check model
Total Count: Total number of queries we have in the training data
Unique Count: Number of unique queries in the training data
Edit Distance Distribution: Distribution of the edit distances so that we get to know the occurrence of a given edit distance between a pair of wrong and correct query
Query Length Distribution: Creating a distribution of query lengths by counting the length of each query
3. TRAINING**:*
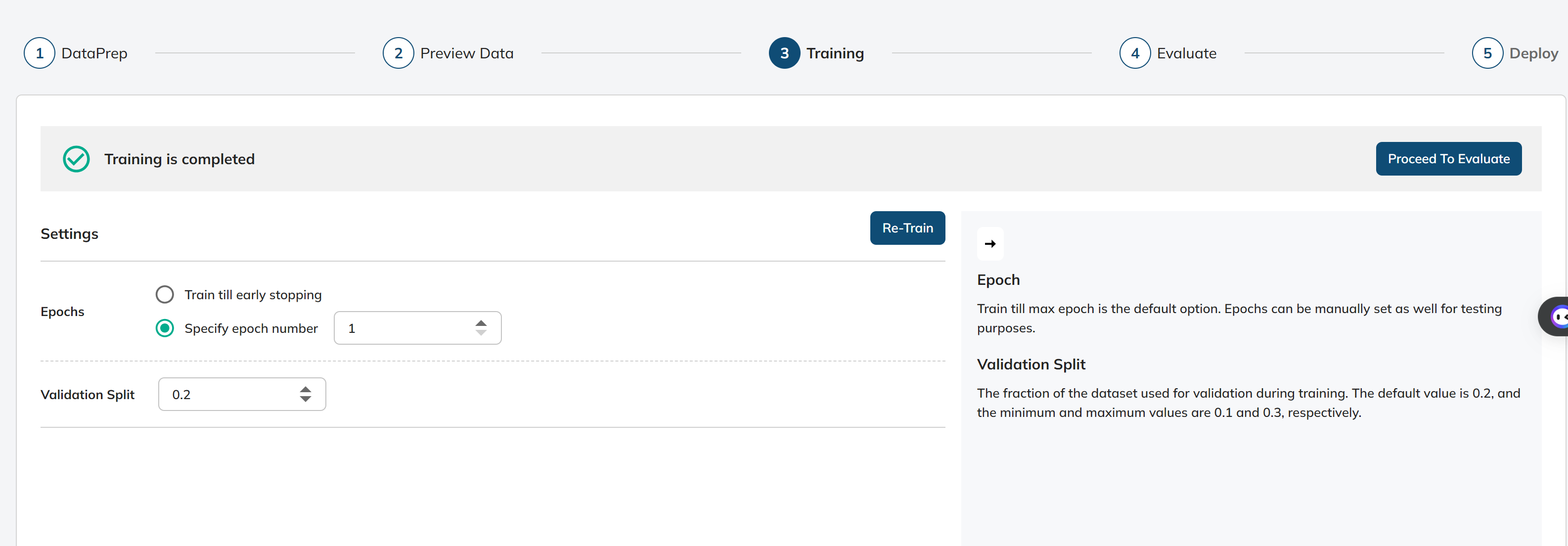
Epoch:
- Definition: The number of times the model should be trained on the entire dataset.
- Train till max epoch is the default option. Epochs can be manually set as well for testing purposes.
- Early Stopping: Early stopping is a technique in machine learning where the training process is halted once a certain criterion, such as the lack of improvement in a validation metric, is met. It helps prevent overfitting and allows the model to generalize better to unseen data.
- Purpose: Epochs determine how many times the model will iterate over the entire dataset during training. A higher number of epochs can lead to better model performance, but it may also increase the risk of overfitting, especially if the dataset is small.
Validation Split:
- Definition: The fraction of the dataset used for validation during training.
- Default Value: 0.2
- Minimum Value: 0.1
- Maximum Value: 0.3
- Purpose: The validation split determines the portion of the dataset that is set aside for validation to monitor the model's performance during training. A larger validation split can provide better feedback on model performance but reduces the size of the training dataset.
- EVALUATION:
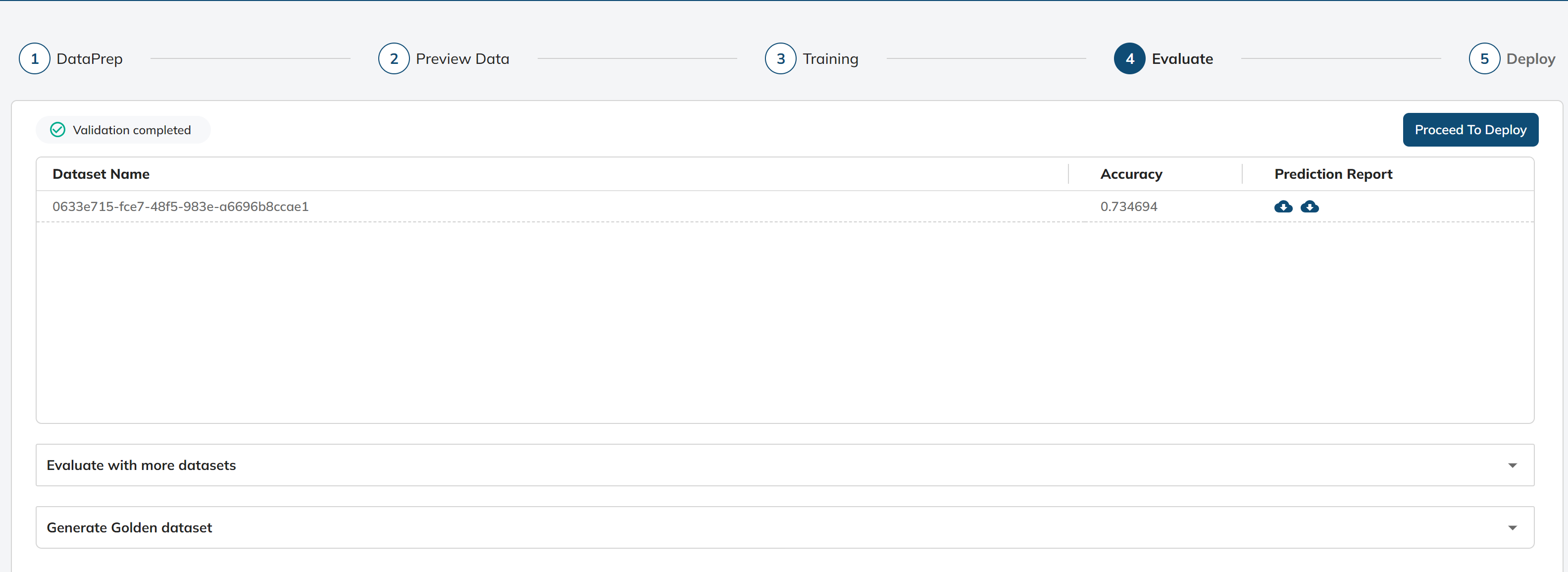
In this particular stage, we facilitate the evaluation of our spell check model by providing the following sample datasets:-
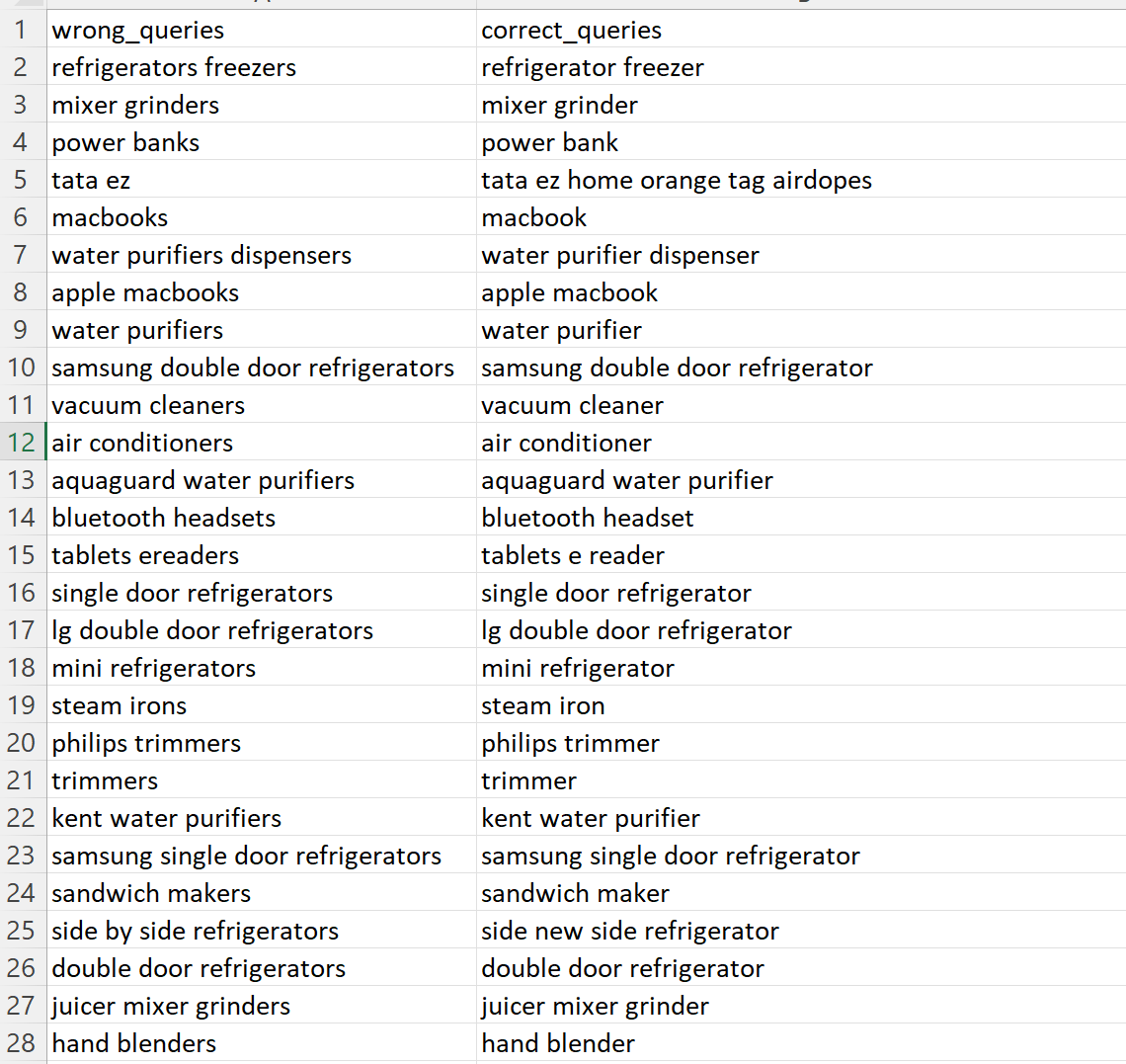
These sample datasets are meticulously prepared and formatted to mimic the structure of real-world data. By offering these datasets, we aim to assess the model's performance in accurately categorizing user queries.
The primary purpose of these sample datasets is to gauge the model's effectiveness in assigning appropriate corrected queries to a set of predefined queries. This evaluation process allows us to calculate scores that reflect the model's accuracy, which are key metrics for measuring its spell checking performance.
The sample dataset can be uploaded for the evaluation of the model trained to check the performance of the model. After selection, we can click the “Start Validation” button.
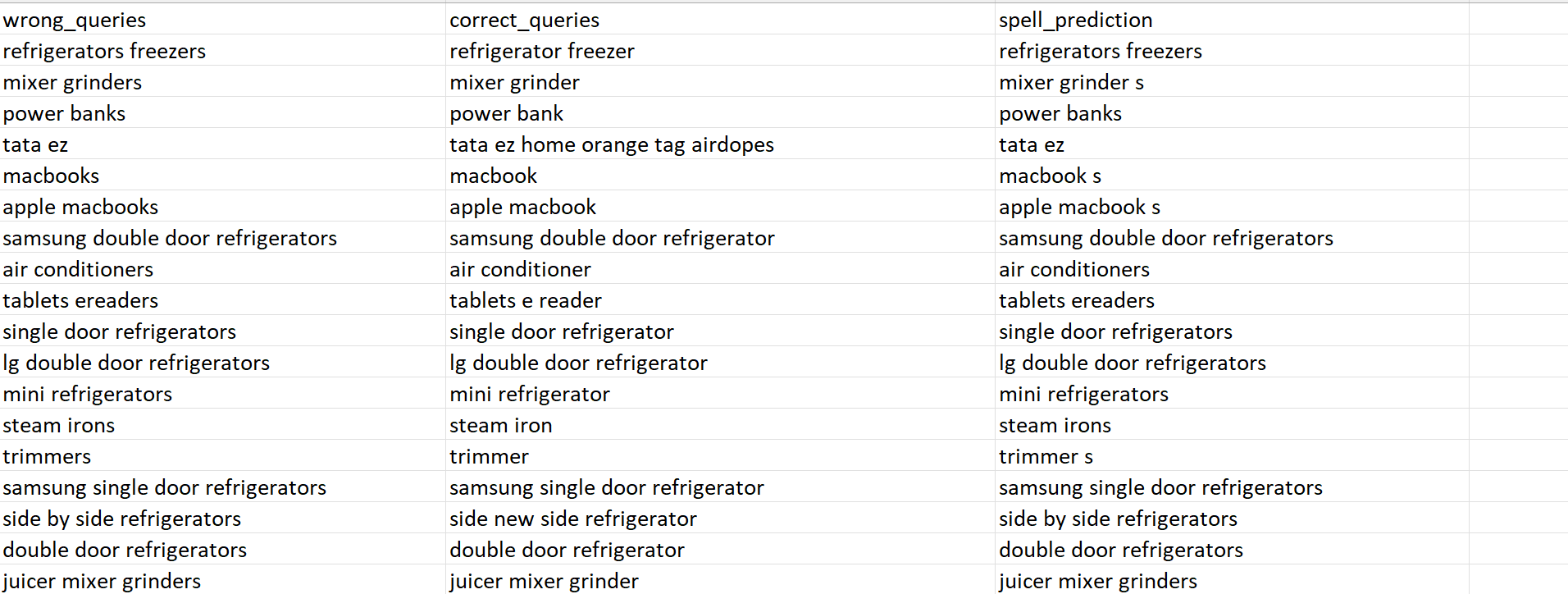
Following the evaluation process, the system generates accuracy of the model.
Additionally, it provides the option to download the prediction report files. These files offer detailed insights into the model's performance, such as actual corrected query, predicted corrected query from the spell checl model, and the discrepancies between them.
Generate Golden Set:
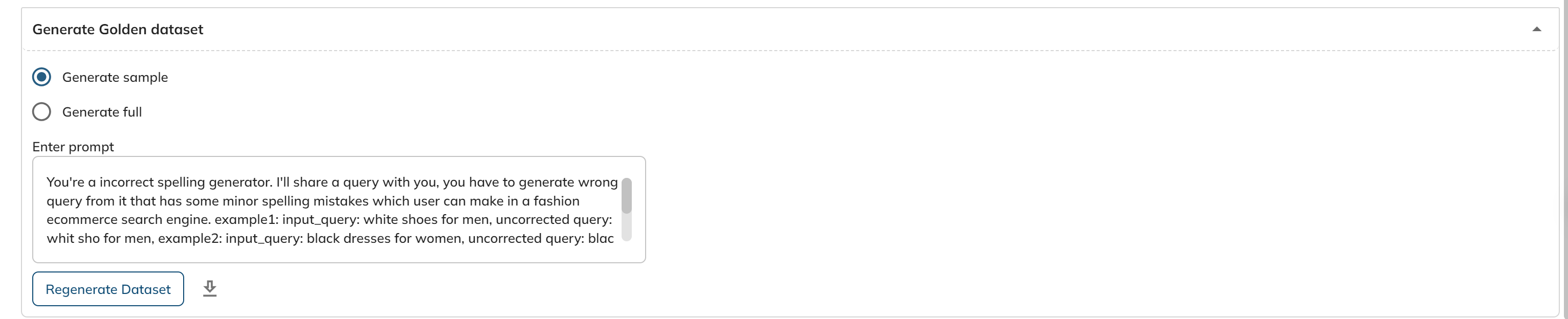
We can generate testing dataset using GPT. We can choose whether we want to generate a sample on or full dataset. And have to enter the prompt as well.
Generate golden dataset section will help in creating golden dataset from scratch which will be used for evaluation. We can select between sample and full. Sample is for generating golden set for 500 records and can be downloaded for verification also. Full generation will be generated for 20,000 records and once the generation is completed, it will be sent to the dataset group which can be used for evaluation.
Generation:-
- Retrieve the first queries from the past 180 days.
- fetch the top 300,000 most viewed search terms for products within the last 180 days, ordering them by total views. Then, it randomly samples 20,000 search terms from this subset, starting from the 100,000th term.
- If click stream is enabled for the client, then it retrieves search terms from ‘search_product_metrics’ and get corrected query for all these search terms using GPT.
- if click stream is disabled for the client, then it retrieves AI keywords from ‘ai_product_keywords’ and ‘ai_category_keywords’ table and get uncorrected query for these keywords
- DEPLOY:
After successfully training and evaluating the model, the next crucial step is deployment, where the model is made accessible and operational for use in real-world applications or services. This phase marks the transition from a research or development environment to practical, everyday use.
Next, in the Test Your Model we will provide a query - “aple iphon 13“.
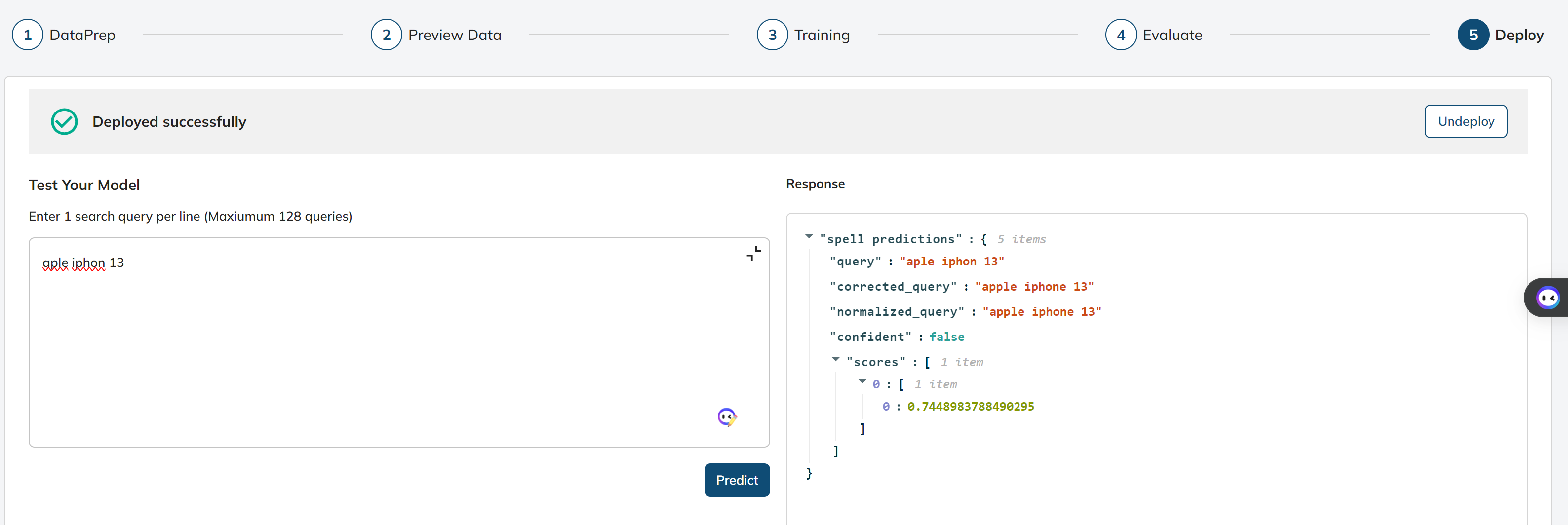
- Test Your Model: This is a stage in the deployment process where you can test the deployed model's performance by providing search queries and receiving corrected queries. To get the response, we can click the “Predict” button.
- Response: This will represent the response or results of the model's predictions for the provided search queries.
query: The input search queries provided by the user.
corrected_query: corrected query predicted by the deployed model.
normalised_query: represent the query after applying a normalization process
confidence
scores
Once we have verified that the model is functioning flawlessly, we can proceed to deploy it for practical use by simply clicking the "Deploy" button.
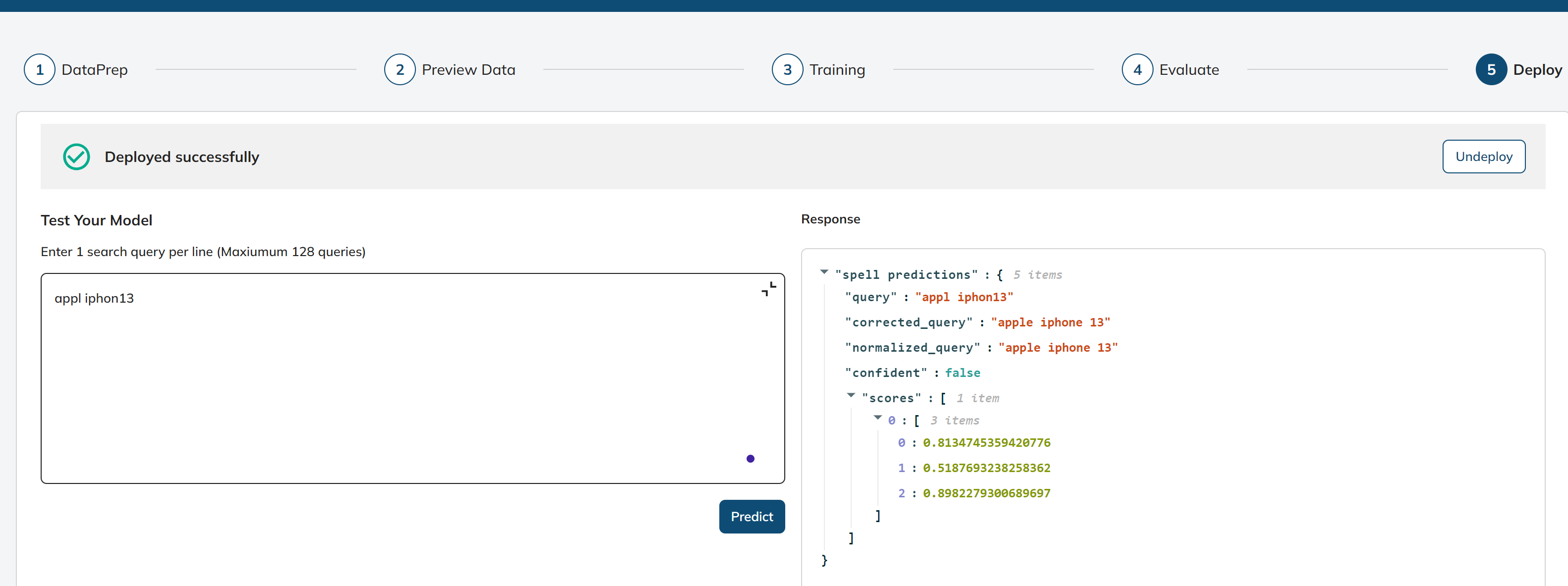
If needed, we can also deactivate or remove the deployed model by clicking the "Undeploy" button.